


AI 战胜人类三冠王,索尼曲线救国储备自动驾驶技术?

Deep Blue 以 3.5:2.5 赢了国际象棋冠军卡斯帕罗夫、AlphaGo 以 3:1 击败世界围棋冠军柯洁、Libratus 在和顶尖德州扑克选手的比赛中胜出、AlphaStar 以总比分 2:0 击败《星际争霸 2》顶级选手……
过去的几十年里, AI 不断刷新人们的认知并在各种游戏中接连打败人类顶尖选手。而索尼也在上周四整了一出大新闻:
2 月 9 日,索尼宣布开发出了一款名为 GT Sophy 的 AI,在索尼为 PS 平台推出的赛车游戏 Gran Turismo Sport(GT Sport) 中,作为 AI 车手的 GT Sophy 表现神勇,在比赛中胜过了历史上第一个 GT 锦标赛三冠王 TAKUMA MIYAZONO、2020 国际汽联大奖赛冠军 RYOTA KOKUBUN、2019/2020 年 GT 锦标赛冠军 TOMOAKI YAMANAKA 和 2019 年 GT 锦标赛亚军 SHOTARO RYU。
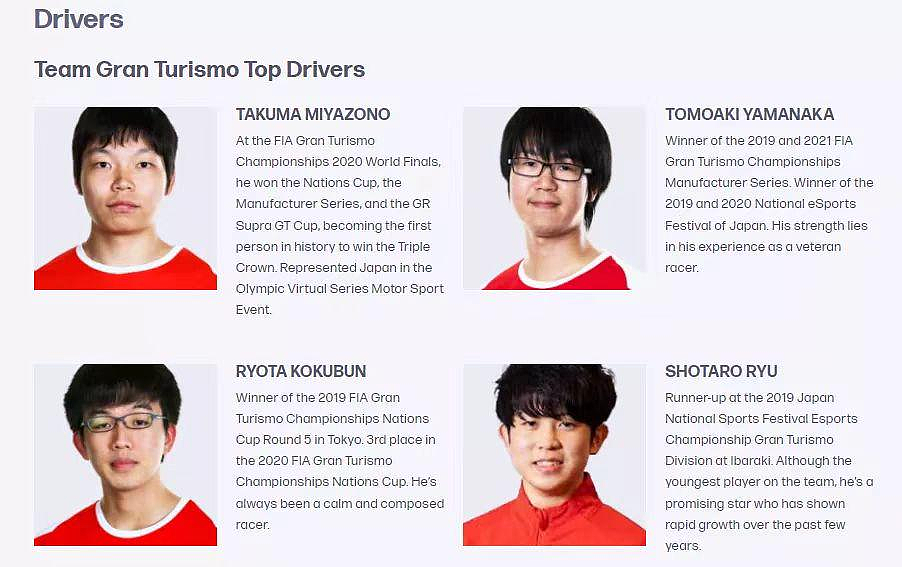
该成果也登上了 Nature 杂志的封面。

如果你对这款游戏有过了解,那么你一定知道 GT Sport 和极品飞车、极限竞速地平线 4 这种娱乐向的游戏完全不同。在 GT Sport 中,索尼尽可能地重现现实世界的赛车环境,包括赛车的载荷、传动比、动力输出、轮胎附着力甚至空气阻力等。
顶尖的赛车手会在训练中实现「条件反射」,对油门的开度、轮胎的滑移、进弯或出弯的时间点、路感反馈等信息作出瞬间的反应和微调,最终将赛车逼向极限。

但不可否认的是,这些信息的底层逻辑都是物理定律,人类无论如何也无法在控制能力上和机器平起平坐,更何况 GT Sophy 拥有精确的赛道路线地图和每个轮胎负载、其他车辆状态等精确信息。
为了让 AI 和人类顶尖车手在对战尽量公平,研究人员将 GT Sophy 的反应时间调低至 100 毫秒、200 毫秒和 250 毫秒,与之相对,人类车手训练后的反应时间大约为 150 毫秒。除此之外,GT Sophy 的输入被限制在 10 Hz,而人类的理论的最大输入值是 60 Hz。
01 GT Sophy 实战表现如何?
惊艳的控车技术
在赛车比赛中,「外—内—外」的走线是时间最短的方式。虽然一直贴着内弯在距离上看最短,但这样会让车辆进出弯的速度落差极大,不利于出弯后的再加速。
受到侧向加速度的影响,车辆在半径较大的弧线上的行驶速度会比半径小的弧线上快得多。所以,以「外—内—外」的方式过弯可以看成车辆行驶过一个更大半径的圆弧,如此车辆的速度损失最小。

在 GT Sophy 的比赛实况里我们可以清楚地看到,AI 赛车手在入弯前极限地紧贴外弯边缘,进入弯心后立即再次加速,划过一道近乎完美的圆弧。

整个过程非常流畅,速度损失也降到最低。而在连续弯道中,GT Sophy 甚至会大幅度地吃路肩来保证行车路线最短。
凌厉的弯道超车
赛车在高速行驶时会在车前部形成一个正压区,而气流在车尾分离形成负压区,前后的压力差是空气阻力的主要来源。

可以看到,GT Sophy 在直道上紧紧咬住前车,此时它处于前车形成的真空区内,阻力减小。在进入弯道时,GT Sophy 向左抽头企图超车,但此时前车封线,右边没有了超车空间。GT Sophy 没有犹豫,略微减速后选择向左进攻并完成超车。
在整个过程中,GT Sophy 不仅要考虑到自己的行车路线最优化,还需要根据对手的行为迅速给出对应策略。这种双车对抗的情景具有高度的不确定性,但可以看到 GT Sophy 的表现丝毫不拖泥带水。
良好的体育精神
关注赛车运动的人一定记得去年 9 月 12 日,在 F1 意大利蒙扎大奖赛上汉密尔顿和维斯塔潘发生碰撞,双双退赛。

究其原因,其实是轮胎温度更好的维斯塔潘企图在弯道时超越汉密尔顿,而就在维斯塔潘即将完成超车时汉密尔顿却向弯角打了一把方向,直接堵死了维斯塔潘的行车路线。这也让两人不可避免地撞在了一起。

为了避免这种过于偏激的驾驶行为存在,索尼的工作人员特意为 GT Sophy 训练了赛道礼仪的规则。可以在演示视频中看到,GT Sophy 驾驶的白色保时捷911 在超越对手时并没有像汉密尔顿一样堵死对手的行车线,而是给对方留出了足够的行车空间。这种谦让的操作让 GT Sophy 在比赛中具有了和人类一样的「温度」。
02 技惊四座,原理是啥?
GT Sophy 在和人类顶尖车手的决斗中表现稳定且凌厉,在看比赛视频时我被它各种游走在极限的操作惊讶到合不拢嘴。那么问题来了,是什么缔造了这个强悍的 AI 赛车手?
深度学习 & 强化学习各有局限
在解释 GT Sophy 使用的深度强化学习技术之前,有必要先解释一下我们常说的「深度学习」和「强化学习」的概念。
简单来说,人工智能包含了机器学习,而深度学习和强化学习都属于机器学习的范畴。

深度学习可以简单分为监督学习和无监督学习,本质都是教会算法在大量数据中寻找规律并最终可以自己辨认事物,在这个过程中,作为中间环节的函数则需要尽可能准确的拟合出输入数据和输出结果的关系,这正是具有强大拟合能力的神经网络的强项。
举一个简单的例子,如果想教会 AI 辨认猫和狗,第一种方法是在大量猫狗照片中通过标注特征教会其识别两者的区别,神经网络不断学习并最终拟合出多个「万能近似函数」,最终实现无限逼近输出目标。这属于深度学习中的「监督学习」。
相对的,「无监督学习」则是让 AI 自己寻找大量数据中的共性,AI 会把自己认为相似的东西分为一组,虽然它不知道谁是猫、谁是狗,但是也能区分出两者。
深度学习的特质让其非常适合用来处理目标识别的任务。最近几年,神经网络模型越来越成熟,其在识别任务中的准确率也越来越接近人类。但是这只是自动驾驶中「感知」中的部分,单纯深度学习对于「决策」层面的作用就很有限了。
而在解释强化学习之前,首先明确两个强化学习中的基本概念:Environment 和 Agent。智能体(Agent)处在一个环境(Environment)中,每个状态为智能体对当前环境的感知;智能体只能通过动作来影响环境,当智能体执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给智能体一个奖赏。
在与环境的互动中,AI 需要不断地改变自己的行为策略,做出对环境变化最好的应对策略以期望奖励最大化。
仔细想想我们自己学习知识的过程,是不是似曾相识?没错,强化学习的范式和人类的学习过程非常类似,所以它也被视为最终实现通用 AI 的希望之光。
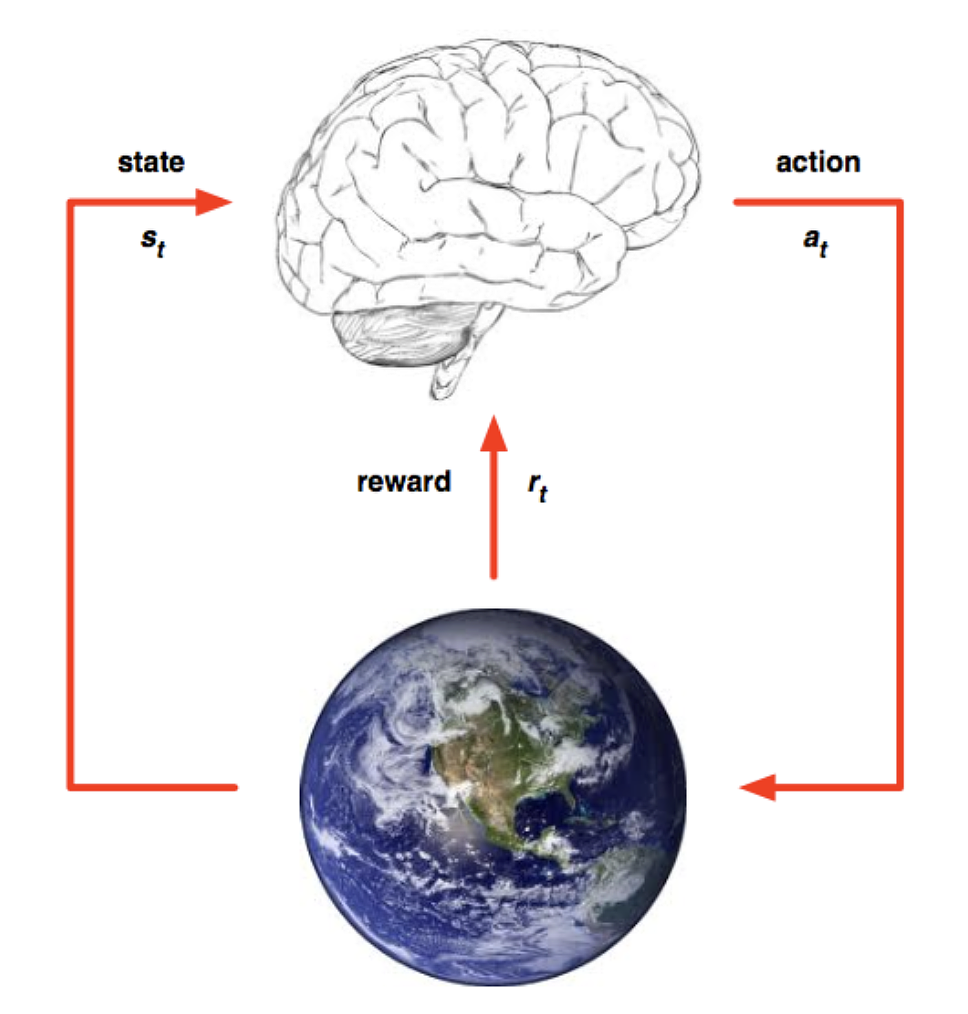
相信你也发现了:在车辆自动驾驶的语境下,环境的变化实在是过于复杂,对手动作的变化、自己的操作、赛道的变化都会让结果改变。传统的强化学习只能在经验中寻找跟眼前状态一样的案例并模仿作出决策,基本没有泛化和预测能力。
深度强化学习横空出世
GT Sophy 将深度学习在函数拟合方面的优势和强化学习在决策方面的优势结合,把深度学习应用在期望奖励趋势预测中,最终实现未知环境下更好的行为表现。
我们来具体看看 GT Sophy 是怎么做的:
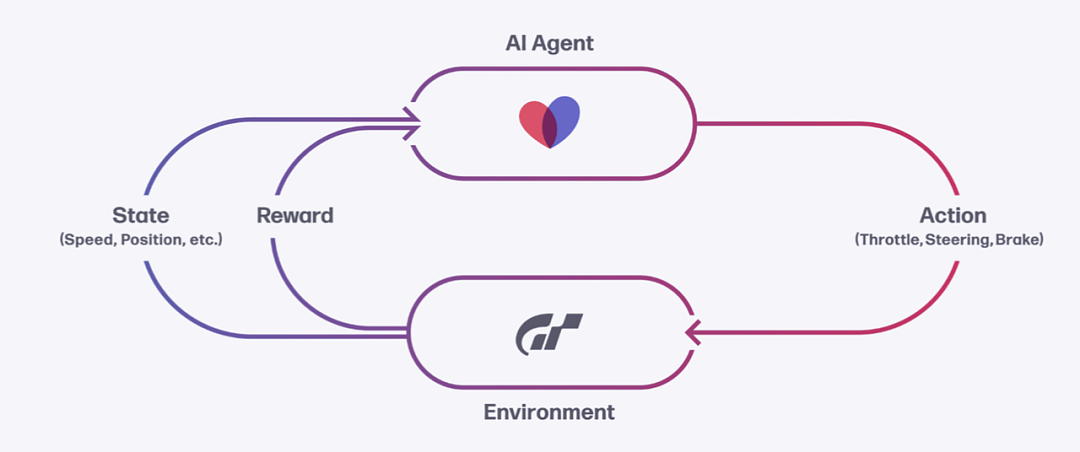
上图中包含了强化学习的几个基本设定:
Agent 和 Enviroment 分别代表智能体和交互的环境;
Action:Agent 做出的所有动作,包括油门开度、转向、刹车等;
State:Agent 所有能够感知到的状态,包括车辆的速度、位置、赛道情况等;
Reward:设定好的奖励或者惩罚。
根据此,我们再来延伸出强化学习中的一个进阶概念:「Policy」。
Policy 是指智能体(Agent)在状态(State )下需要做出的行为(Action)决策。它可以看成 Agent 从 State 到 Action 的映射,是一个函数。
在 GT Sport 这款游戏里,游戏场景是 Enviroment,GT Sophy 是 Agent,赛车的各个状态是 State,对赛车的操作是 Action,怎么操作赛车是 Policy。

为了知晓如何做出最佳的动作决策,需要算法预判当前感知到的状态和做出的行为对未来有何影响,在奖励函数的参考下,Agent 会最终给出决策。
传统的强化学习在表示状态和动作时采用表格形式,这就导致这种方法无法适用于大范围的动作和状态变化。而且如果一个状态从未出现过,此时算法就会完全不知道怎么处理。
说白了,传统强化学习是根据发生过的行为得出的结论来指导下一次学习。但回想一下,人类是怎么处理事情的?人类会将眼前发生的事情和记忆里类似的情况进行比对,如果相似则采取相似的做法,不会死板地照搬照抄。

GT Sophy 的创新点正是在此,不论有没有感知过一模一样的状态都能通过深度学习来拟合,相近的状态可以得到相似的动作结果,所有的输入都能有结果产生。

GT Sophy 在奖励函数和惩罚函数的指导下,对上文中所说的行为结果产生后进行评估,如果得到了正向的奖励,它会以此为经验,不断向完美操作行为逼近;如果得到了负面的惩罚,GT Sophy 会调整自己的参数,不断试错直到获得奖励。这就让 GT Sophy 可以自己在环境中迅速成长并积累经验。

这些让 GT Sophy 在几小时内就学会了跑完整条赛道,超过了 95% 的人类驾驶员。而通过 45,000 小时的训练,GT Sophy 在选定的三条赛道上超越了 177,000 名玩家。
但只设定有圈速进步的奖励机制会让 GT Sophy 学会偷懒。如果对手足够快,GT Sophy 会选择跟随他而不是风险更大的超越他,GT Sophy 会评估更有效获得奖励的方式。
研究人员改变了奖励函数和惩罚函数的设定,将 GT Sophy 和对手的距离与奖励设定为成正比。与之相对,如果对手从后方接近,惩罚的力度也和接近 GT Sophy 的距离成正比。
但这又产生了另外一个问题。由于设定改变,GT Sophy 的驾驶行为会变得过于激进。同时,赛车游戏不同于棋类游戏的零和博弈,可以出现两方均有收益或两方均损失的状态。
比如,如果 GT Sophy 跟车过近,而对手选择的刹车点比它要早,这就不可避免发生严重碰撞,研究人员最后选择将任何碰撞都设定为惩罚。

上图是 GT Sophy 奖励函数/惩罚函数的各个部分及其权重:
Rcp:GT Sophy 的行车轨迹进步程度;
Rsoc 或 Rloc:驶出赛道惩罚;
Rw:接触赛场墙壁惩罚;
Rts:轮胎滑移惩罚;
Rps:超车奖励;
Rc:和对手碰撞惩罚;
Rr:追尾惩罚;
Ruc:非进攻性驾驶碰撞惩罚(防止 GT Sophy 害怕撞击而过于保守)。
这些奖励惩罚函数的细化和研究人员对参数的不断细微调整,最终让 GT Sophy 在保证最快圈速的同时学会了赛车礼仪。
如上文所述,虽然 GT Sophy 可以自行搜集数据完成迭代,但场景的不足可能会让其产生「偏科」的现象。比如训练的场景中,对手如果一直选择贴右入弯,GT Sophy 只能学会向左超车。
研究人员为此开发了一个「混合场景训练」的过程。在与人类玩家比赛的过程中,研究人员会找出 GT Sophy 表现不好的场景,针对这些场景单独设置训练。

最后,在作为比赛地图的三个场地里,GT Sophy 都取得了压倒性优势。

03 索尼自动驾驶技术储备?
在 2022 年的北美 CES 大会上,索尼董事长、总裁兼首席执行官吉田健一郎宣布索尼集团将成立新的部门——索尼移动出行公司,该部门预计在今年春季成立。吉田健一郎称「我们正在探索索尼电动车的商业化。」
这也意味着,索尼正式确定造车了。那么 GT Sophy 成果上的技术储备能为索尼未来的自动驾驶提供多少帮助?
先要泼一盆冷水:在游戏中,地图信息、路面材质和其他车辆当前的状态信息等都是完美被算法知晓的状态,天气状况也并不极端,这就相当于自动驾驶感知到的信息非常完美。而在现实中,各家车企为提高传感器精度、多传感器融合等问题想破了脑袋。
而且赛道作为行驶场景非常单一,没有红绿灯、复杂的道路线以及穿行的行人,也不会像实际行驶过程中出现那么多的 Corner Case。
这些让 GT Sophy 在很短的时间内就能在赛车模拟器中打败人类,也让算法的训练过程工作量减轻很多,但这并不表明 GT Sophy 的诞生毫无用处。
特斯拉的规控、自动标注和仿真的负责人 Ashok 在去年的 AI DAY 上展示了特斯拉在面临「三车相遇」和「停车场自动泊车入位」两个复杂场景下的决策表现,使用和 GT Sophy 同样的深度强化学习技术的车辆近乎完美地在这两个场景中实现了自动决策。

在「停车场自动泊车入位」的场景下,使用了基于蒙特卡洛树框架的深度强化学习算法的车辆相较于使用传统 A* 算法的车辆在路径规划过程中的表现更为完美,搜索效率提升了 100 倍以上。
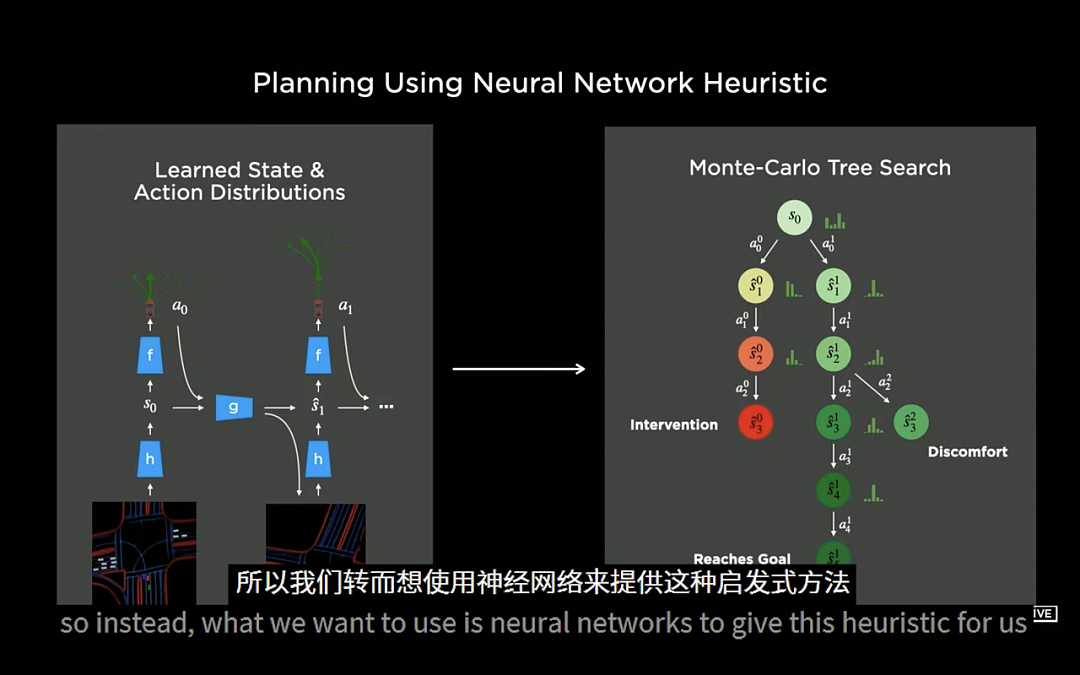
特斯拉使用深度强化学习技术处理自动驾驶决策的方案表现不错并初步落地,这证明该技术的确具有非常广阔的前景,目前各家自动驾驶公司也都把此作为研发的方向。
说回索尼造车这件事,早在 2014 年索尼就将车载 CMOS 图像传感器商业化,2021 年 9 月,索尼半导体解决方案集团宣布自己研发的面向高精度激光雷达的传感器 IMX 459 可以实现 300 m 外 15 cm 的识别精度,在对角线距离 6.25 mm 的芯片上搭载了约 10 万个 10 平方微米的像素,满足高精度和高速的测量需求。

并且在 2020 年和 2021 年的 CES 大会上,索尼称 VISION-S 原型车将搭载 40 个传感器并可以实现 L2+ 级别的辅助驾驶功能。


尽管索尼没有明确表示 GT Sophy 的相关成果会应用于造车,但斯坦福大学汽车研究中心主任 Chris Gerdes 教授表示:
「GT Sophy 在赛道上的成功表明,有朝一日神经网络在自动驾驶汽车软件上的作用会比现在更大。」
本文来自微信公众号“42号车库”(ID:i42how),作者:明明,36氪经授权发布。




 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


