


到底什么是 ASIC 和 FPGA?
上一篇文章(链接),小枣君给大家介绍了 CPU 和 GPU。今天,我继续介绍计算芯片领域的另外两位主角 ——ASIC 和 FPGA。
█ASIC(专用集成电路)
上篇提到,GPU 的并行算力能力很强,但是它也有缺点,就是功耗高,体积大,价格贵。
进入 21 世纪后,算力需求呈现两个显著趋势:一,算力的使用场景,开始细分;二,用户对算力性能的要求,越来越高。通用的算力芯片,已经无法满足用户的需求。
于是,越来越多的企业,开始加强对专用计算芯片的研究和投资力度。而 ASIC(Application Specific Integrated Circuit,专用集成电路),就是一种专用于特定任务的芯片。

ASIC 的官方定义,是指:应特定用户的要求,或特定电子系统的需要,专门设计、制造的集成电路。
ASIC 起步于上世纪 70-80 年代。早期的时候,曾用于计算机。后来,主要用于嵌入式控制。这几年,如前面所说,开始崛起,用于 AI 推理、高速搜索以及视觉和图像处理等。
说到 ASIC,我们就不得不提到 Google 公司大名鼎鼎的TPU。

TPU,全称 Tensor Processing Unit,张量处理单元。所谓“张量(tensor)”,是一个包含多个数字(多维数组)的数学实体。
目前,几乎所有的机器学习系统,都使用张量作为基本数据结构。所以,张量处理单元,我们可以简单理解为“AI 处理单元”。
2015 年,为了更好地完成自己的深度学习任务,提升 AI 算力,Google 推出了一款专门用于神经网络训练的芯片,也就是 TPU v1。
相比传统的 CPU 和 GPU,在神经网络计算方面,TPU v1 可以获得 15~30 倍的性能提升,能效提升更是达到 30~80 倍,给行业带来了很大震动。
2017 年和 2018 年,Google 又再接再厉,推出了能力更强的 TPU v2 和 TPU v3,用于 AI 训练和推理。2021 年,他们推出了 TPU v4,采用 7nm 工艺,晶体管数达到 220 亿,性能相较上代提升了 10 倍,比英伟达的 A100 还强 1.7 倍。
除了 Google 之外,还有很多大厂这几年也在捣鼓 ASIC。
英特尔公司在 2019 年底收购了以色列 AI 芯片公司 Habana Labs,2022 年,发布了 Gaudi 2 ASIC 芯片。IBM 研究院,则于 2022 年底,发布了 AI ASIC 芯片 AIU。
三星早几年也搞过 ASIC,当时做的是矿机专用芯片。没错,很多人认识 ASIC,就是从比特币挖矿开始的。相比 GPU 和 CPU 挖矿,ASIC 矿机的效率更高,能耗更低。

ASIC 矿机
除了 TPU 和矿机之外,另外两类很有名的 ASIC 芯片,是DPU和NPU。
DPU 是数据处理单元(Data Processing Unit),主要用于数据中心。小枣君之前曾经专门介绍过,可以看这里:火遍全网的 DPU,到底是个啥?
NPU 的话,叫做神经网络处理单元(Neural Processing Unit),在电路层模拟人类神经元和突触,并用深度学习指令集处理数据。
NPU 专门用于神经网络推理,能够实现高效的卷积、池化等操作。一些手机芯片里,经常集成这玩意。
说到手机芯片,值得一提的是,我们手机现在的主芯片,也就是常说的 SoC 芯片,其实也是一种 ASIC 芯片。

手机 SoC 芯片
ASIC 作为专门的定制芯片,优点体现在哪里?只是企业独享,专用 logo 和命名?
不是的。
定制就是量体裁衣。基于芯片所面向的专项任务,芯片的计算能力和计算效率都是严格匹配于任务算法的。芯片的核心数量,逻辑计算单元和控制单元比例,以及缓存等,整个芯片架构,也是精确定制的。
所以,定制专用芯片,可以实现极致的体积、功耗。这类芯片的可靠性、保密性、算力、能效,都会比通用芯片(CPU、GPU)更强。
大家会发现,前面我们提到的几家 ASIC 公司,都是谷歌、英特尔、IBM、三星这样的大厂。
这是因为,对芯片进行定制设计,对一家企业的研发技术水平要求极高,且耗资极为巨大。
做一款 ASIC 芯片,首先要经过代码设计、综合、后端等复杂的设计流程,再经过几个月的生产加工以及封装测试,才能拿到芯片来搭建系统。
大家都听说过“流片(Tape-out)”。像流水线一样,通过一系列工艺步骤制造芯片,就是流片。简单来说,就是试生产。
ASIC 的研发过程是需要流片的。14nm 工艺,流片一次需要 300 万美元左右。5nm 工艺,更是高达 4725 万美元。
流片一旦失败,钱全部打水漂,还耽误了大量的时间和精力。一般的小公司,根本玩不起。
那么,是不是小公司就无法进行芯片定制了呢?
当然不是。接下来,就轮到另一个神器出场了,那就是 ——FPGA。
█FPGA(现场可编程门阵列)
FPGA,英文全称 Field Programmable Gate Array,现场可编程门阵列。
FPGA 这些年在行业里很火,势头比 ASIC 还猛,甚至被人称为“万能芯片”。
其实,简单来说,FPGA 就是可以重构的芯片。它可以根据用户的需要,在制造后,进行无限次数的重复编程,以实现想要的数字逻辑功能。
之所以 FPGA 可以实现 DIY,是因为其独特的架构。
FPGA 由可编程逻辑块(Configurable Logic Blocks,CLB)、输入 / 输出模块(I / O Blocks,IOB)、可编程互连资源(Programmable Interconnect Resources,PIR)等三种可编程电路,以及静态存储器 SRAM 共同组成。
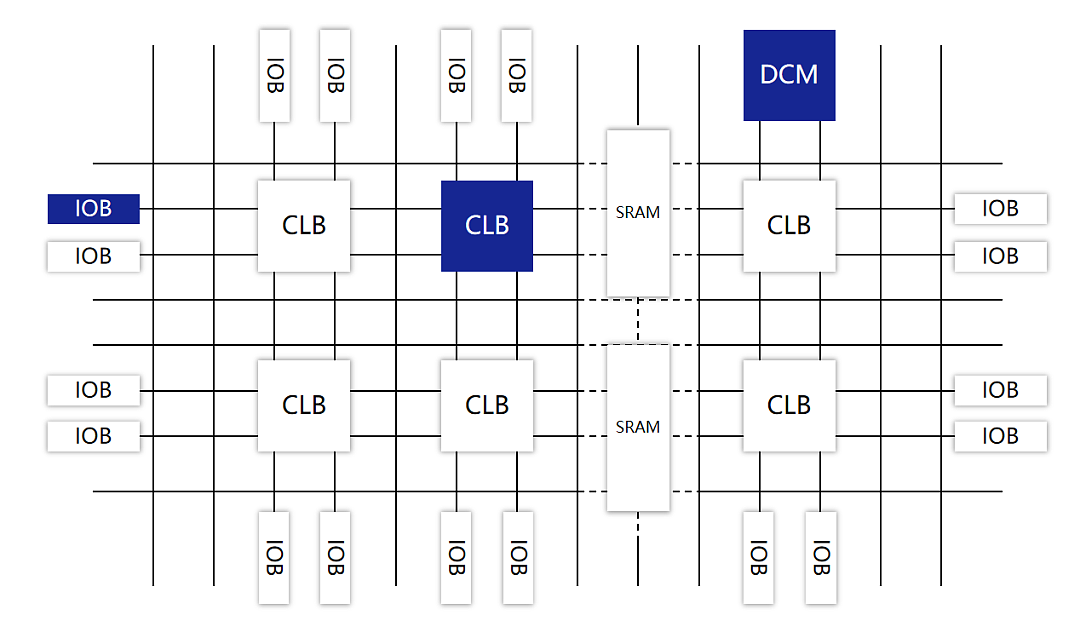
CLB 是 FPGA 中最重要的部分,是实现逻辑功能的基本单元,承载主要的电路功能。
它们通常规则排列成一个阵列(逻辑单元阵列,LCA,Logic Cell Array),散布于整个芯片中。
IOB 主要完成芯片上的逻辑与外部引脚的接口,通常排列在芯片的四周。
PIR 提供了丰富的连线资源,包括纵横网状连线、可编程开关矩阵和可编程连接点等。它们实现连接的作用,构成特定功能的电路。
静态存储器 SRAM,用于存放内部 IOB、CLB 和 PIR 的编程数据,并形成对它们的控制,从而完成系统逻辑功能。
CLB 本身,又主要由查找表(Look-Up Table,LUT)、多路复用器(Multiplexer)和触发器(Flip-Flop)构成。它们用于承载电路中的一个个逻辑“门”,可以用来实现复杂的逻辑功能。
简单来说,我们可以把 LUT 理解为存储了计算结果的 RAM。当用户描述了一个逻辑电路后,软件会计算所有可能的结果,并写入这个 RAM。每一个信号进行逻辑运算,就等于输入一个地址,进行查表。LUT 会找出地址对应的内容,返回结果。
这种“硬件化”的运算方式,显然具有更快的运算速度。
用户使用 FPGA 时,可以通过硬件描述语言(Verilog 或 VHDL),完成的电路设计,然后对 FPGA 进行“编程”(烧写),将设计加载到 FPGA 上,实现对应的功能。
加电时,FPGA 将 EPROM(可擦编程只读存储器)中的数据读入 SRAM 中,配置完成后,FPGA 进入工作状态。掉电后,FPGA 恢复成白片,内部逻辑关系消失。如此反复,就实现了“现场”定制。
FPGA 的功能非常强大。理论上,如果 FPGA 提供的门电路规模足够大,通过编程,就能够实现任意 ASIC 的逻辑功能。

FPGA 开发套件,中间那个是 FPGA 芯片
我们再看看 FPGA 的发展历程。
FPGA 是在 PAL(可编程阵列逻辑)、GAL(通用阵列逻辑)等可编程器件的基础上发展起来的产物,属于一种半定制电路。
它诞生于 1985 年,发明者是 Xilinx 公司(赛灵思)。后来,Altera(阿尔特拉)、Lattice(莱迪思)、Microsemi(美高森美)等公司也参与到 FPGA 这个领域,并最终形成了四巨头的格局。
2015 年 5 月,Intel(英特尔)以 167 亿美元的天价收购了 Altera,后来收编为 PSG(可编程解决方案事业部)部门。
2020 年,Intel 的竞争对手 AMD 也不甘示弱,以 350 亿美元收购了 Xilinx。
于是,就变成了 Xilinx(AMD 旗下)、Intel、Lattice 和 Microsemi 四巨头(换汤不换药)。
2021 年,这四家公司的市占率分别为 51%、29%、7% 和 6%,加起来是全球总份额的 93%。
不久前,2023 年 10 月,Intel 宣布计划拆分 PSG 部门,独立业务运营。
国内 FPGA 厂商的话,包括复旦微电、紫光国微、安路科技、东土科技、高云半导体、京微齐力、京微雅格、智多晶、遨格芯等。看上去数量不少,但实际上技术差距很大。
█ASIC 和 FPGA 的区别
接下来,我们重点说说 ASIC 和 FPGA 的区别,还有它们和 CPU、GPU 之间的区别。
ASIC 和 FPGA,本质上都是芯片。AISC 是全定制芯片,功能写死,没办法改。而 FPGA 是半定制芯片,功能灵活,可玩性强。
我们还是可以通过一个例子,来说明两者之间的区别。
ASIC 就是用模具来做玩具。事先要进行开模,比较费事。而且,一旦开模之后,就没办法修改了。如果要做新玩具,就必须重新开模。
而 FPGA 呢,就像用乐高积木来搭玩具。上手就能搭,花一点时间,就可以搭好。如果不满意,或者想搭新玩具,可以拆开,重新搭。

ASIC 与 FPGA 的很多设计工具是相同的。在设计流程上,FPGA 没有 ASIC 那么复杂,去掉了一些制造过程和额外的设计验证步骤,大概只有 ASIC 流程的 50%-70%。最头大的流片过程,FPGA 是不需要的。
这就意味着,开发 ASIC,可能需要几个月甚至一年以上的时间。而 FPGA,只需要几周或几个月的时间。
刚才说到 FPGA 不需要流片,那么,是不是意味着 FPGA 的成本就一定比 ASIC 低呢?
不一定。
FPGA 可以在实验室或现场进行预制和编程,不需要一次性工程费用 (NRE)。但是,作为“通用玩具”,它的成本是 ASIC(压模玩具)的 10 倍。
如果生产量比较低,那么,FPGA 会更便宜。如果生产量高,ASIC 的一次性工程费用被平摊,那么,ASIC 反而便宜。
这就像开模费用。开模很贵,但是,如果销量大,开模就划算了。
如下图所示,40W 片,是 ASIC 和 FPGA 成本高低的一个分界线。产量少于 40W,FPGA 便宜。多于 40W,ASIC 便宜。
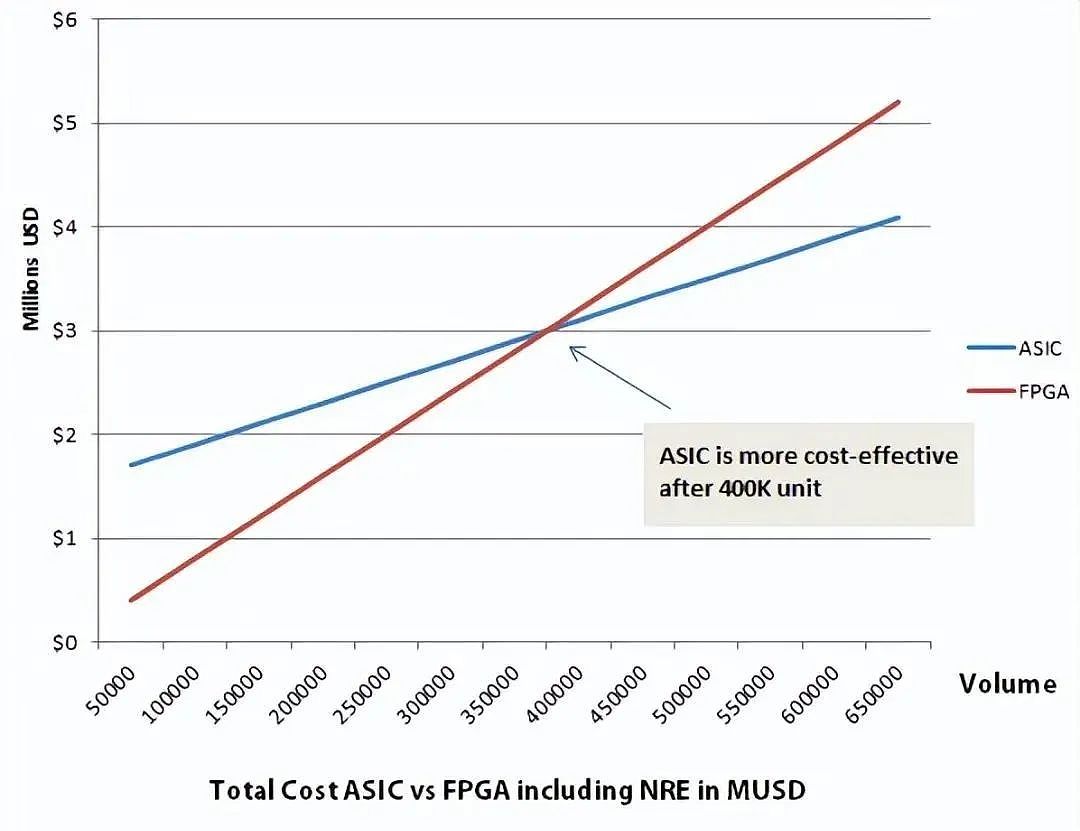
从性能和功耗的角度来看,作为专用定制芯片,ASIC 是比 FPGA 强的。
FPGA 是通用可编辑的芯片,冗余功能比较多。不管你怎么设计,都会多出来一些部件。
前面小枣君也说了,ASIC 是贴身定制,没什么浪费,且采用硬连线。所以,性能更强,功耗更低。
FPGA 和 ASIC,不是简单的竞争和替代关系,而是各自的定位不同。
FPGA 现在多用于产品原型的开发、设计迭代,以及一些低产量的特定应用。它适合那些开发周期必须短的产品。FPGA 还经常用于 ASIC 的验证。
ASIC 用于设计规模大、复杂度高的芯片,或者是成熟度高、产量比较大的产品。
FPGA 还特别适合初学者学习和参加比赛。现在很多大学的电子类专业,都在使用 FPGA 进行教学。
从商业化的角度来看,FPGA 的主要应用领域是通信、国防、航空、数据中心、医疗、汽车及消费电子。
FPGA 在通信领域用得很早。很多基站的处理芯片(基带处理、波束赋形、天线收发器等),都是用的 FPGA。核心网的编码和协议加速等,也用到它。数据中心之前在 DPU 等部件上,也用。
后来,很多技术成熟了、定型了,通信设备商们就开始用 ASIC 替代,以此减少成本。
值得一提的是,最近这些年很热门的 Open RAN,其实很多都是采用通用处理器(Intel CPU)进行计算。这种方案的能耗远远不如 FPGA 和 ASIC。这也是包括华为等设备商不愿意跟进 Open RAN 的主要原因之一。
汽车和工业领域,主要是看中了 FPGA 的时延优势,所以会用在 ADAS(高级驾驶辅助系统)和伺服电机驱动上。
消费电子用 FPGA,是因为产品迭代太快。ASIC 的开发周期太长了,等做出东西来,黄花菜都凉了。
█FPGA、ASIC、GPU,谁是最合适的 AI 芯片?
最后,我们还是要绕回到 AI 芯片的话题。
上一期,小枣君埋了一个雷,说 AI 计算分训练和推理。训练是 GPU 处于绝对领先地位,而推理不是。我没有说原因。
现在,我来解释一下。
首先,大家要记住,单纯从理论和架构的角度,ASIC 和 FPGA 的性能和成本,肯定是优于 CPU 和 GPU 的。

CPU、GPU 遵循的是冯・诺依曼体系结构,指令要经过存储、译码、执行等步骤,共享内存在使用时,要经历仲裁和缓存。
而 FPGA 和 ASIC 并不是冯・诺依曼架构(是哈佛架构)。以 FPGA 为例,它本质上是无指令、无需共享内存的体系结构。
FPGA 的逻辑单元功能在编程时已确定,属于用硬件来实现软件算法。对于保存状态的需求,FPGA 中的寄存器和片上内存(BRAM)属于各自的控制逻辑,不需要仲裁和缓存。
从 ALU 运算单元占比来看,GPU 比 CPU 高,FPGA 因为几乎没有控制模块,所有模块都是 ALU 运算单元,比 GPU 更高。
所以,综合各个角度,FPGA 的运算速度会比 GPU 更快。
再看看功耗方面。
GPU 的功耗,是出了名的高,单片可以达到 250W,甚至 450W(RTX4090)。而 FPGA 呢,一般只有 30~50W。
这主要是因为内存读取。GPU 的内存接口(GDDR5、HBM、HBM2)带宽极高,大约是 FPGA 传统 DDR 接口的 4-5 倍。但就芯片本身来说,读取 DRAM 所消耗的能量,是 SRAM 的 100 倍以上。GPU 频繁读取 DRAM 的处理,产生了极高的功耗。
另外,FPGA 的工作主频(500MHz 以下)比 CPU、GPU(1~3GHz)低,也会使得自身功耗更低。FPGA 的工作主频低,主要是受布线资源的限制。有些线要绕远,时钟频率高了,就来不及。
最后看看时延。
GPU 时延高于 FPGA。
GPU 通常需要将不同的训练样本,划分成固定大小的“Batch(批次)”,为了最大化达到并行性,需要将数个 Batch 都集齐,再统一进行处理。
FPGA 的架构,是无批次(Batch-less)的。每处理完成一个数据包,就能马上输出,时延更有优势。
那么,问题来了。GPU 这里那里都不如 FPGA 和 ASIC,为什么还会成为现在 AI 计算的大热门呢?
很简单,在对算力性能和规模的极致追求下,现在整个行业根本不在乎什么成本和功耗。
在英伟达的长期努力下,GPU 的核心数和工作频率一直在提升,芯片面积也越来越大,属于硬刚算力。功耗靠工艺制程,靠水冷等被动散热,反而不着火就行。
除了硬件之外,上篇文章小枣君也提到,英伟达在软件和生态方面很会布局。
他们捣鼓出来的 CUDA,是 GPU 的一个核心竞争力。基于 CUDA,初学者都可以很快上手,进行 GPU 的开发。他们苦心经营多年,也形成了群众基础。
相比之下,FPGA 和 ASIC 的开发还是太过复杂,不适合普及。
在接口方面,虽然 GPU 的接口比较单一(主要是 PCIe),没有 FPGA 灵活(FPGA 的可编程性,使其能轻松对接任何的标准和非标准接口),但对于服务器来说,足够了,插上就能用。
除了 FPGA 之外,ASIC 之所以在 AI 上干不过 GPU,和它的高昂成本、超长开发周期、巨大开发风险有很大关系。现在 AI 算法变化很快,ASIC 这种开发周期,很要命。
综合上述原因,GPU 才有了现在的大好局面。
在 AI 训练上,GPU 的算力强劲,可以大幅提升效率。
在 AI 推理上,输入一般是单个对象(图像),所以要求要低一点,也不需要什么并行,所以 GPU 的算力优势没那么明显。很多企业,就会开始采用更便宜、更省电的 FPGA 或 ASIC,进行计算。
其它一些算力场景,也是如此。看重算力绝对性能的,首选 GPU。算力性能要求不那么高的,可以考虑 FPGA 或 ASIC,能省则省。
█最后的话
关于 CPU、GPU、FPGA、ASIC 的知识,就介绍到这里了。
它们是计算芯片的典型代表。人类目前所有的算力场景,基本上都是由它们在负责。
随着时代的发展,计算芯片也有了新的趋势。例如,不同算力芯片进行混搭,互相利用优势。我们管这种方式,叫做异构计算。另外,还有 IBM 带头搞的类脑芯片,类似于大脑的神经突触,模拟人脑的处理过程,也获得了突破,热度攀升。以后有机会,我再和大家专门介绍。
希望小枣君的芯片系列文章对大家有所帮助。喜欢的话,求关注,求转发,求点赞。
感谢!
参考文献:
1、《一文搞懂 GPU 的概念、工作原理》,开源 LINUX;
2、《AI 芯片架构体系综述》,知乎,Garvin Li;
3、《GPU、FPGA、ASIC 加速器有什么区别?》,知乎,胡说漫谈;
4、《带你深入了解 GPU、FPGA 和 ASIC》,汽车产业前线观察;
5、《为什么 GPU 是 AI 时代的算力核心》,沐曦集成电路;
6、《一文通览自动驾驶三大主流芯片架构》,数字化转型;
7、《AIGC 算力全景与趋势报告》,量子位;
8、百度百科、维基百科。
本文来自微信公众号:鲜枣课堂 (ID:xzclasscom),作者:小枣君
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。




 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


